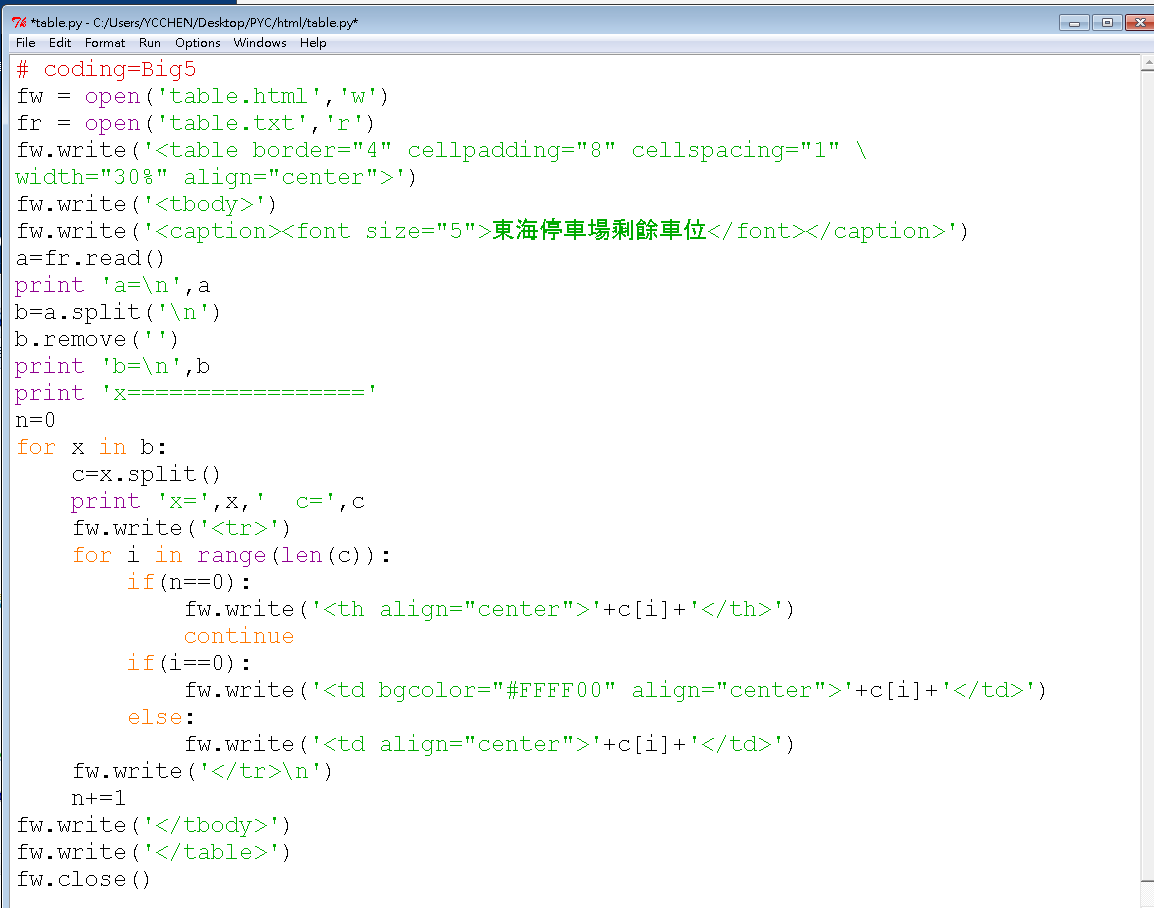
####--------output on the screen-----------
a=
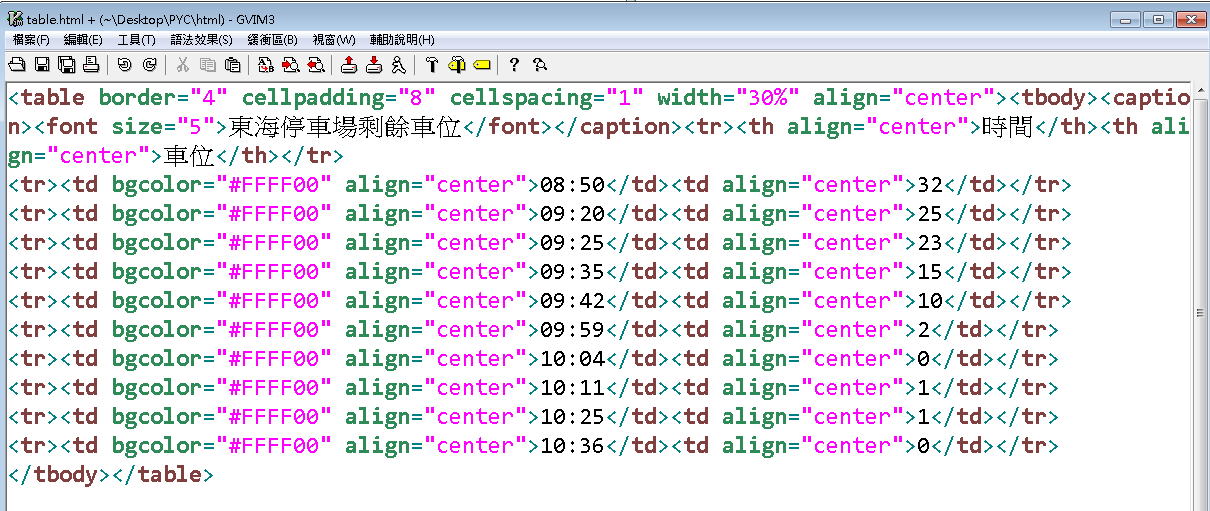
時間 車位
08:50 32
09:20 25
09:25 23
09:35 15
09:42 10
09:59 2
10:04 0
10:11 1
10:25 1
10:36 0
b=
['\xae\xc9\xb6\xa1\t\xa8\xae\xa6\xec', '08:50\t32', '09:20\t25', '09:25\t23', '09:35\t15', '09:42\t10', '09:59\t2', '10:04\t0', '10:11\t1', '10:25\t1', '10:36\t0']
x=================
x= 時間 車位 c= ['\xae\xc9\xb6\xa1', '\xa8\xae\xa6\xec']
x= 08:50 32 c= ['08:50', '32']
x= 09:20 25 c= ['09:20', '25']
x= 09:25 23 c= ['09:25', '23']
x= 09:35 15 c= ['09:35', '15']
x= 09:42 10 c= ['09:42', '10']
x= 09:59 2 c= ['09:59', '2']
x= 10:04 0 c= ['10:04', '0']
x= 10:11 1 c= ['10:11', '1']
x= 10:25 1 c= ['10:25', '1']
x= 10:36 0 c= ['10:36', '0']