python抓蟲範例程式
「網路爬蟲」是一個透過程式「自動抓取」網站資料的過程,在這資訊爆炸的時代中,資料的收集是相當重要的工作項目之一,但如果透過人工的方式來收集網站資料,效率低之外也會花費掉非常多的時間因此資料的收集與整理這份工作,可以透過網路爬蟲來協助,我們只要先制定好規則,網路爬蟲就可以自動依照這規則收集和擷取資料並整理出我們所需的格式,像是 Excel 試算表、CSV 檔案或是資料庫等。-
學習重點1: requests
import requests from bs4 import BeautifulSoup FW=open('cim1.html','w',encoding='UTF-8') url = 'https://movies.yahoo.com.tw/movie_thisweek.html' response = requests.get(url=url) s=response.text FW.write(s) FW.close()cim1.html就是程式中抓取的網址的網頁內容: https://movies.yahoo.com.tw/movie_thisweek.html
-
學習重點2:BeautifulSoup
import requests from bs4 import BeautifulSoup url = 'https://movies.yahoo.com.tw/movie_thisweek.html' response = requests.get(url=url) FW4=open('cim4.html','wb') soup = BeautifulSoup(response.text, 'lxml') info_items = soup.find_all('div', 'release_info') for item in info_items: name = item.find('div', 'release_movie_name').a.text.strip() english_name = item.find('div', 'en').a.text.strip() release_time = item.find('div', 'release_movie_time').text.split(':')[-1].strip() level = item.find('div', 'leveltext').span.text.strip() s=name+'=='+english_name+'=='+release_time+'=='+level+'
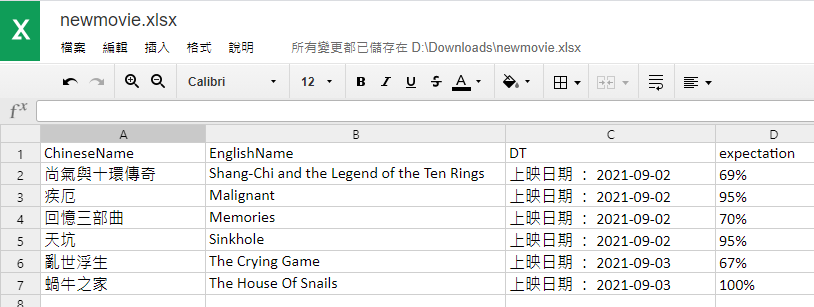
\n' b=bytes(s,encoding="cp950") FW4.write(b) FW4.close()疾厄==Malignant==上映日期 : 2021-09-02==95%
回憶三部曲==Memories==上映日期 : 2021-09-02==70%
天坑==Sinkhole==上映日期 : 2021-09-02==95%
亂世浮生==The Crying Game==上映日期 : 2021-09-03==67%
蝸牛之家==The House Of Snails==上映日期 : 2021-09-03==100%
-
學習重點3:write data into csv
import requests from bs4 import BeautifulSoup url = 'https://movies.yahoo.com.tw/movie_thisweek.html' response = requests.get(url=url) FW4=open('cim4.html','wb') soup = BeautifulSoup(response.text, 'lxml') info_items = soup.find_all('div', 'release_info') for item in info_items: name = item.find('div', 'release_movie_name').a.text.strip() english_name = item.find('div', 'en').a.text.strip() release_time = item.find('div', 'release_movie_time').text.split(':')[-1].strip() level = item.find('div', 'leveltext').span.text.strip() s=name+'=='+english_name+'=='+release_time+'=='+level+'
\n' b=bytes(s,encoding="cp950") FW4.write(b) FW4.close()import csv info_items = soup.find_all('div', 'release_info') with open('newmovie.csv', 'w', encoding='utf-8', newline='') as csv_file: csv_writer = csv.writer(csv_file) csv_writer.writerow(['ChineseName', 'EnglishName', 'DT', 'expectation']) for item in info_items: name = item.find('div', 'release_movie_name').a.text.strip() english_name = item.find('div', 'en').a.text.strip() release_time = item.find('div', 'release_movie_time').text.split(':')[-1].strip() level = item.find('div', 'leveltext').span.text.strip() csv_writer.writerow([name, english_name, release_time, level]) 擷取的資料,儲存至 csv 檔案中:newmovie.csv